はじめに:第二の脳に、自分以外の書き手を増やしたい
Obsidianを「第二の脳」として使っている人は多いと思う。
PC・Windows端末・スマホと複数台をまたいで同じVaultを開き、Remotely Save経由でS3にバックアップ兼同期させる。 この構成自体は、もう一般的なノウハウになっている。
筆者も同じ構成で運用していた。
どの端末からメモを書いても、他の端末にすぐ反映される。 典型的な第二の脳のインフラだ。
ただ、ある時ふと気づいた。 この第二の脳は、いつも「自分が書く」ことが前提になっている。
- 自分が気づく
- 自分が要約する
- 自分が分類する
- 自分が保存する
メンテナンスは100%自分の作業だ。
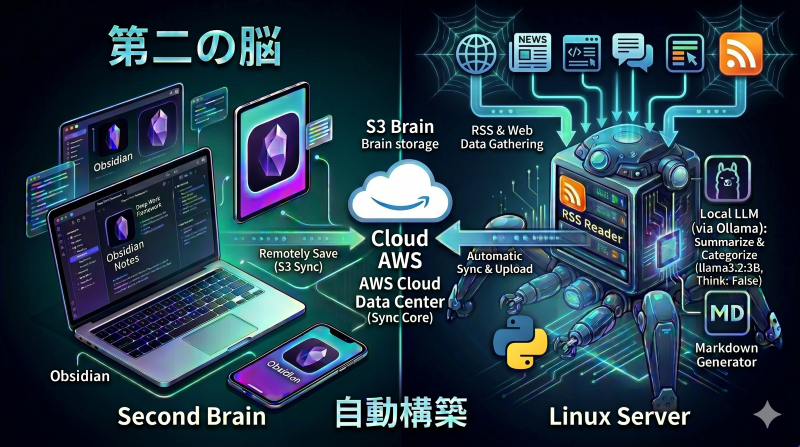
ここにローカルLLMを追加したらいいかもしれんということで、自宅に常時起動しているZorinOSとして稼働するLinuxサーバ(以下「Tachikoma」と呼ぶ)に、もう一本の手を持たせることにした。 興味あるサイトのRSSを巡回させ、ローカルLLMで要約・分類し、Obsidian形式のメモとして自動生成、Remotely Syncの先であるS3に直接アップロードする役割だ。
尚、LinuxサーバのTachikoma自体にObsidianアプリは不要である。
同期の輪に入っていなくても、S3という共通の置き場所に直接ファイルを送り込めば、結果的に第二の脳の一部になるわけだからね。
そんなわけで構成は以下になる。
[PC] ──┐
[Windows端末] ──┼── Remotely Save ──→ [S3バケット]
[スマホ] ──┘ ↑
│ 直接アップロード
[Tachikoma(Linuxサーバー)]
RSS収集 → ローカルLLMで要約・分類
→ Markdown生成 → S3へ3端末で育てている第二の脳に、AIが自動で情報を運んでくる4本目の手が加わった、というイメージだ。
構成の紹介はここまで。
次に、Linuxサーバ上でローカルLLM+Pythonによる実装を進める過程でローカルLLMの扱いにいくつも詰まったので、その記録を残す。
なぜクラウドAPIではなく、ローカルLLMなのか
まずは当然出てくる疑問がある。
OpenAIやAnthropicのAPIを使えば、もっと速く、もっと精度の高い要約・分類ができるのではないか。 実際その通りだと思う。
ただ、今回はローカルLLMでいくことにした。理由は3つ。
1. タスクがそもそも即時性を求めていない
ChatGPTやClaudeのWebチャットのように、人間が画面の前で今すぐ答えを待つタスクではない。 RSSを2時間おきに巡回し、深夜から早朝にかけて静かに記事を集め、起きたときにObsidianを開けば情報がまとまっている、という運用だ。 レスポンスが数秒だろうと数十秒だろうと、体感差はほとんどない。 待てるタスクと待てないタスクを分けて考えると、これは明確に前者だった。
2. 即時性を求めてないのでコストをかけたくない
RSSは14件のフィードを2時間おきに巡回する構成だ。 1記事あたり要約・分類・コメント生成で計3回のAPI呼び出しが必要になるので、月単位で見ると呼び出し回数は小さくない。 クラウドAPIの従量課金でこれを延々と回し続けるのは、個人の検証・運用としては気が引ける。 電気代はかかるが、すでに動かしている自宅サーバーを使い倒す方が財布にやさしい。
3. 最近のローカルLLMの進化に対して、実際どこまで使えるのか試したかった
正直、これが一番の動機でもある。
数年前のローカルLLMは「動くだけで偉い」というレベルで、実務に組み込める精度ではなかった印象がある。 だが最近は、2B〜3B級の小型モデルでも要約や簡単な分類なら十分戦力になる、という話をよく見かける。
普段はChatGPTからClaudeに乗り換えた筆者としては、ローカルLLMが実際どこまで使えるのか、自分の手で検証したかった。
結論を先に言うと、使える、ただし設計次第というのが今回の実感だ。
モデルを正しく選び、求める処理の解像度をモデルの規模に見合った範囲に収めれば、2時間おきの巡回バッチくらいは十分にローカルで回せる。
逆に、何も考えずデフォルト設定のまま動かすと、痛い目を見る。
その「痛い目」の記録が、ここからの内容だ。
発端:たった一言の挨拶に3分
検証はシンプルな一言から始まった。
curl -s http://localhost:11434/api/generate -d '{
"model": "qwen3.5:2b",
"prompt": "こんにちはと一言だけ返してください",
"stream": false
}'これだけの返信に返ってくるまで2分52秒。
たった2Bパラメータのモデルが、挨拶を返すだけでこれだけかかるのはおかしい。
仮説1:GPUが非力すぎるのでは
Tachikomaに積んでいるGPUを確認すると、Quadro T1000(VRAM 4GB)だった。 LLM推論用のGPUではなく、業務PC向けのディスプレイ出力用GPUだ。 ollama psで見ると、CPU/GPU比率は52%/48%。ほぼ半分がCPU推論に回っている。
非力なGPUが足を引っ張っているのでは、と考え、フルCPU推論(8コアXeon)と比較してみた。
| 構成 | 速度 |
|---|---|
| CPU/GPU混在(デフォルト) | 2分52秒 |
フルCPU(num_gpu: 0) | 3分51秒 |
結果は逆だった。 非力なGPUでも、何もないよりはあった方が速い。 ハードウェアの配分は、最適化の余地があるように見えて、実は的外れな仮説だった。
本当の原因:Thinkモードそのもの
ここで思い出したのが、Qwen3.5系がデフォルトで搭載しているThinkモードだ。
プロンプトを受け取ると、回答の前に内部で延々と「思考過程」を生成する仕組みである。
簡単な挨拶ひとつにも、律儀に数百〜千トークン規模の思考してから、ようやく本題に答える。
まさにログを見たらこの思考を見たら延々と繰り返し自問自答して、ようやく最終的な回答が出ていることがわかった。
そこでこれは無効化すべきと考えた。
まず最初は/no_thinkという制御文字列をプロンプトやModelfileのSYSTEM命令に埋め込めば無効化できると思っていた。 が、これがことごとく効かなかった。
理由は単純で、比較的新しいOllamaのAPIでは、Thinkの有効/無効はプロンプト内の文字列ではなく、リクエストボディ直下の専用パラメータで制御する仕様に変わっていたからだ。
curl -s http://localhost:11434/api/generate -d '{
"model": "qwen3.5:2b",
"prompt": "こんにちはと一言だけ返してください",
"stream": false,
"think": false
}'これで結果は一変した。
| 設定 | 速度 |
|---|---|
| Think有効 | 2分52秒 |
Think無効(think: false) | 1.4秒 |
約120倍の速度差。 ボトルネックの正体は、GPU性能でもCPU性能でもなく、Thinkモードが生成する膨大なトークン量そのものだった。
速度を取ると、精度が落ちた
これで解決かと思いきや、別の問題が出てきた。
Thinkを無効にした状態で実際にニュース記事を要約・分類させると、明らかな誤りが頻発するようになった。
- 記事タイトルにある未知の略語を、存在しない団体名にハルシネーションする
- ヒューマノイドロボットの記事を「PLC」カテゴリに誤分類する
Thinkモードは、応答速度を犠牲にする代わりに、小型モデルの理解力を底上げする補助機能として機能していたわけだ。
速さと精度は、思った以上に強くトレードオフの関係にあった。
カテゴリを減らしても、ブレは収まらなかった
次に試したのは、分類の選択肢を絞ることだ。 「PLC」「Physical AI – 二足歩行」「Physical AI – 四足歩行」「Physical AI – デュアルアーム」「Physical AI – シングルアーム」「製造業DX・その他」という6択は、明らかに小型モデルへの要求として細かすぎた。
同じ記事を複数回処理させると、毎回違うカテゴリに着地した。
| 実行回数 | 判定結果 |
|---|---|
| 1回目 | Physical_AI/Dual_Arm |
| 2回目 | Physical_AI/Single_Arm |
| 3回目 | Physical_AI/Quadrupedal |
temperatureを0.1まで下げて出力のランダム性を抑えても、ブレは収まらなかった。 これは温度設定の問題ではなく、そもそも記事の文面に「ロボットの物理的構造」を判別する情報が存在しないケースが多いことが原因だった。 「ヒューマノイドの社会実装と事業化を議論するイベント」という記事は、ロボットの形態を語る記事ではなく、事業・社会論の記事だからだ。
最終的に、カテゴリを3つ(PLC/Physical AI・ロボティクス/製造業DX・その他)まで統合したところ、3回連続で同じ記事が同じカテゴリに安定して着地するようになった。 選択肢が多すぎることそのものが、モデルにとっての雑音になっていたわけだ。
結局たどり着いた解:そもそもThinkを持たないモデルへ
ここでもうそもそもの視点を変えることにした。
パラメータ上のThinkを「切る」ことに固執せず、そもそもThinkという概念を持たないモデルに切り替えればどうか。
手元にあったllama3.2:latest(軽量・Think非対応)で同じタスクを試したところ、
- 要約:自然な日本語、固有名詞も概ね正確
- 分類(3択への統合後):3回連続で安定
- 速度:15〜30秒程度で完走
Thinkの制御に頭を悩ませる必要が、そもそもなくなった。
まとめ:Thinkは「切る」より「持たないモデルを選ぶ」が早い
今回の検証を一言でまとめると、Obsidian+ローカルLLMで「自動で育つ第二の脳」を作る計画は、うまくいった。
途中の迷走を振り返ると、最初はOllamaに「Thinkモードを無効にしてくれ」と指示すれば済む話だと思っていた。
プロンプトに/no_thinkと書き込んだり、ModelfileのSYSTEM命令で固定したりと、いろいろ試したが、どれも効かなかった。 最終的に分かったのは、こうした文字列レベルの指示はそもそも解釈されず、Think制御はAPIの専用パラメータでしか効かないという仕様の話だった。
そこまで分かった上で、もう一段シンプルな答えに行き着いた。
Thinkを「無効にする」のではなく、最初からThinkを持たないモデルを使えばいい。llama3.2のような軽量モデルに切り替えたところ、速度は十数秒〜数十秒に収まり、要約・分類の精度もこの用途には十分だった。
2時間おきにRSSを巡回し、待てるタスクをコツコツ処理させる――この用途なら、無理に大きいモデルやThink搭載モデルを背伸びして使う必要はなかった。
身の丈にあった選び方が、結果的に一番安定する解だった。
もし今、同じように「ローカルLLMを使いたいが、Thinkモードのせいで遅すぎる」と感じている人がいるなら、伝えたいことは一つだ。/no_thinkのようなプロンプト側の指示や、Modelfile経由のSYSTEM命令をいくら工夫しても、無駄になる可能性が高い。
それよりも先に、次の2つを試してほしい。
- 使っているモデルがThink対応かどうかを確認し、Think制御が必要ならAPIリクエストの専用パラメータ(Ollamaなら
think: falseのような、リクエストボディ直下のオプション)を使う。
プロンプト文字列やSYSTEM命令では効かないことが多い。 - そもそもThinkモードを持たない、もう一段軽量なモデル(例:llama3.2のような3B級モデル)に切り替えてみる。要約や粗い分類程度の用途なら、これで十分な精度が出ることが多く、Thinkの制御に頭を悩ませる必要自体がなくなる。
待てるタスクで、コストもかけたくない――それなら、ローカルLLMは十分選択肢になる。
ただし「Thinkを制御する」より「Thinkがそもそもないモデルを選ぶ」方が、近道であることが多い。
今回の検証から見えた、一番実用的な答えだと感じている。
今回の記事が参考になれば幸いである。
ちなみに、これは今現在のAI技術ではという話であり、今後のAI技術の進化によってはまた見直すことも必要なことは言うまでもない。




