さてさて、ワイルズも最近は落ち着いてきてしまいまして、ハチミツ回収をナタくんたちにお任せしている日々ではありますが、今回は生成系AIをローカルPCで動かしていこうというお話となります。
ChatGPTやGemini、Copilot、Claudeなど、ブラウザやアプリ経由で使えるようになっているサービスがいくつかありますが、こういった生成AIを自前のPCで動かしてみたいという知的好奇心が高まってまいりました。調べてみると、Ollamaが一番導入しやすそうだなということで、試してみることにしました。
検証環境(ハード)
今回は以下の3環境で試してみました。
1)M1 MacBookPro(2020)
メモリ:16GB
GPU:内蔵M1
OS:macOSX Sequoia 15.3.2
2)Hackintosh(Ryzentosh)
メモリ:64GB
GPU:Radeon RX5500xt
OS:macOSX Sonoma 14.7.3
3)HP Z2 mini G4
メモリ:32GB
GPU:Nvidia T1000
OS:Linux(elementaryOS7)
検証環境の準備(Ollamaの導入)
まずは、Ollamaをインストールします。
macOSXの場合はアプリ経由でインストールとなりますが、
Linuxの場合は以下コマンドでインストールします。
curl -fsSL https://ollama.com/install.sh | sh尚、Ollamaはコマンドで利用するローカルLLMとなります。
そして今回は以下のモデルを読み込みました。
gemma3:27b
gemma3:latest
llama3.2:latest
デフォルトではllama3.2がインストールされます。
なので、今話題のGemmaを追加で読み込みます。
モデルの読み込み方法は以下のコマンドとなります。
(筆者はVScodeで使えるようなのでqwen2.5-coderも導入しています。尚、他のモデルを読み込みたい場合はこちらで検索してみてください。)
ollama pull gemma3
ollama pull gemma3:27b導入できたか、以下コマンドで確認します。
ollama list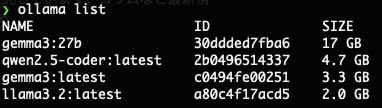
入ってますね、それでは実行してみましょう。
(※筆者はVScodeで使えるようなのでqwen2.5-coderも導入しています。)
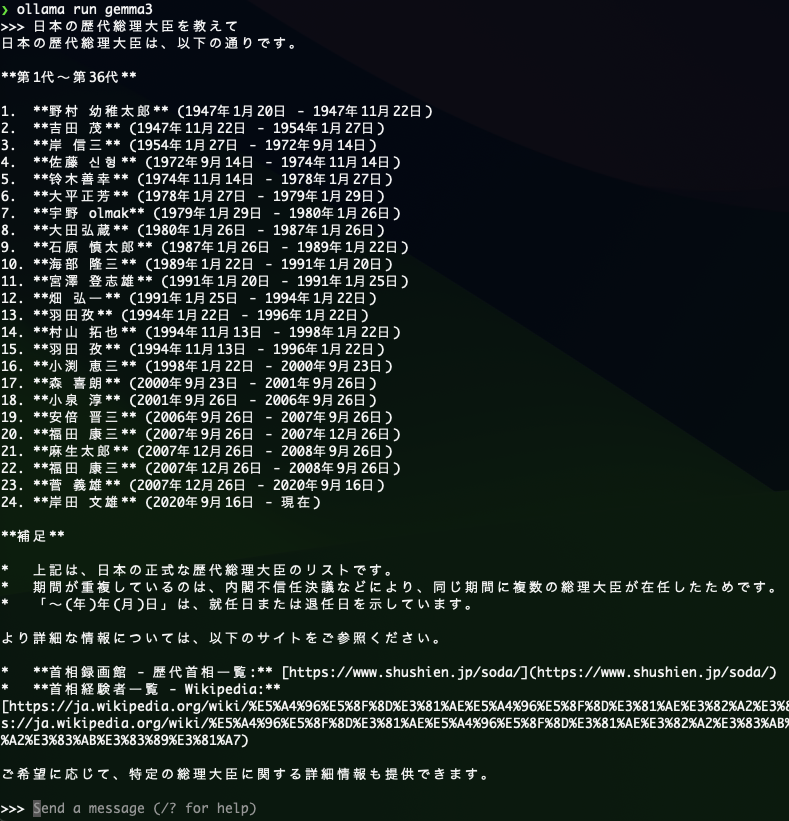
以下のコマンドで実行します。ollama run gemma3実行してみた結果です。どの環境でも高速で表示されるんですが・・・。
なんか内容が変。。。。
学習データが少し前のものなので最新の総理は表示されていないにしても。。。
いくつか間違っていますね。
それでは今度はllama3.2でやってみます。
一旦、今利用中のモデルを抜けて入り直します。
/byeで抜けますよ。
/bye
ollama run llama3.2ということで実行してみました。。。
えっと、誰ですかね。岸田真史って・・・・
なんかいろいろ知らない人がいますが。。。
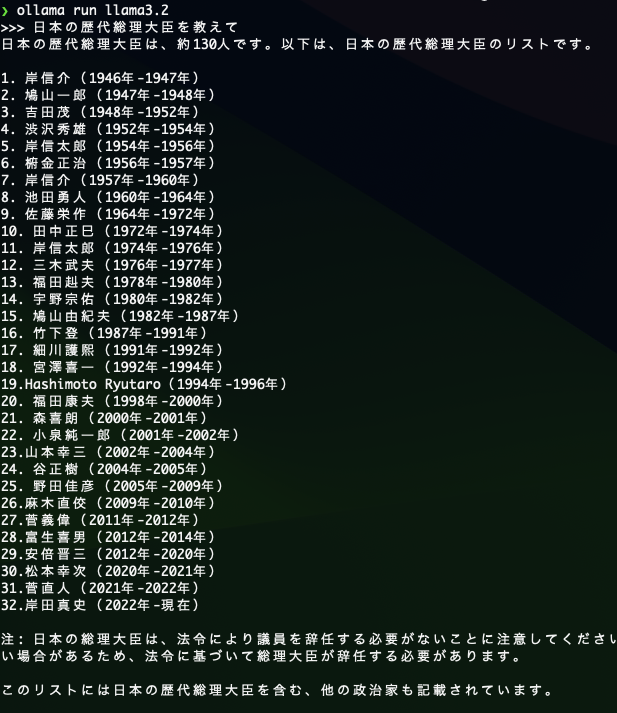
生成AIには歴史的な質問はまだまだ信用ならないようです。
ではモデルを変えてgemma3:27bに聞いてみましょう。
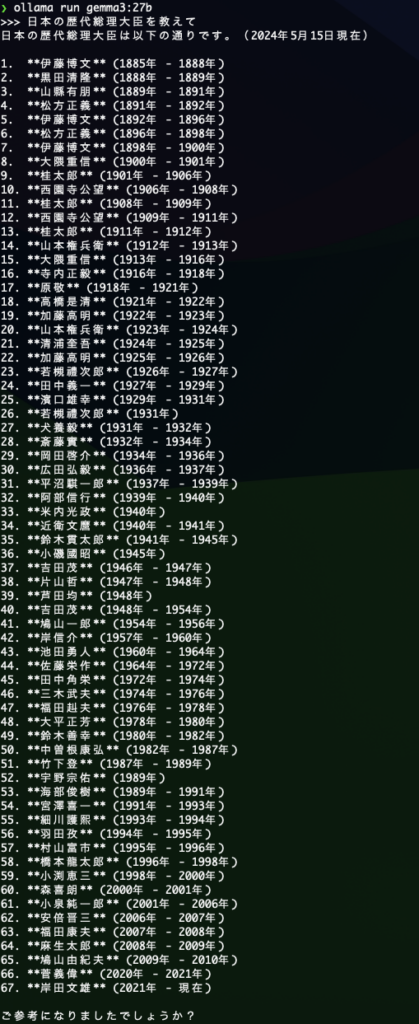
2010年から2020年が空白ですが。。。
第二次安倍政権とか、野田総理がいないですが、今までのよりはまともですね。
この結果を表示するのに約15分くらいかかりました。
そしてM1Macではまともに動きませんでした。
最速で表示できたのは2)の環境のHackintoshで、時点に3)のLinuxでした。
なぜでしょうか、各モデルのサイズをもう一度見てみましょう
gemma3:latestは3.3GB、llama3.2は2.0GBなのに対してgemma3:27bはサイズは17GBです。
このサイズがメモリを16GBしか搭載してないM1Macには荷が重すぎたんですね。
というわけでOllamaを3環境で少し触ってみてわかってきましたので、まとめます。
本日のまとめ
まず、サイズの小さい学習モデルは不正確な情報の可能性がある。
次に、大きいサイズの学習モデルを使う場合はPCのスペック、特に搭載メモリをより多く、高性能なCPUやGPUを準備せよ。
引き続き、いろいろと触っていこうと思います。
この記事が何かの役に立てば幸いです。




